
What makes a good idea
I spent much of my work life at Jung von Matt, a German creative agency known for its pop-culturally iconic campaigns. I was not working on the campaign teams (UX & digital products instead), and in this environment, I (and probably my bosses as well) wouldn’t even consider me particularly “creative”. Being creative in a creative agency means continuously generating and iterating story-driven ideas that tend to be weird, eccentric, unlikely, irrational, surreal — or intensely emotional.
The most important thing I took away from years of working in this environment was an understanding that really good ideas are often based on observations of unspoken truths. Unspoken because people feel ashamed of them or simply can’t put their feelings into words.
If you are unfamiliar, these observations are called “insights”.
To give you some examples, here are three ads that I personally enjoy. Obviously, their writing and production are (were) impeccable. But apart from that, they all share a truth at the core of their ideas, an observation about the audience they try to reach.
“Like a Girl” by Leo Burnett for P&G Always features two insights: One — as mentioned in the ad — is that a girl’s self-esteem plummets with puberty. The other one is that femininity is used as an insult for behavior perceived as weak or sensitive.
The insight of “You’re Not You When You’re Hungry” by BBDO for Snickers is that people’s behavior changes (declines) when their blood sugar levels drop.
“Dumb Ways to Die” by McCann for Metro Trains Australia oozes frustration about the number of people getting injured or even dying in very easily preventable public transport accidents.
I don’t know the behind the scenes of these campaigns. However, all insights could have come either from findings in research papers/industry reports or from pure observation. Often, it is a pingpong of both, iterating and inspiring each other. These findings were then embellished and expanded into funny and serious storytelling ideas while trying to further carve out their deeper truths.
Sensing weak signal
You may have noticed my choice of words in the previous paragraphs, speaking of truths, observations, findings, and insights.
In previous decades, having really good ideas was attributed to the concept of “creative genius,” implying that great ideas manifest out of nowhere. But the reality behind this is much more sobering: It’s gathering as much information about your objective as possible in the least amount of time and, most importantly — throughout your career — developing a sensibility for where to look, as narrow and as broadly as possible.
I call this information-gathering process “The Art of Gentle Stalking”. It includes, but is not limited to:
- Embedding yourself and observing people in the setting of the task / product use
- Active listening to family, friends and the people around you
- Social listening like scanning reviews, signing up to niche forums and groups
- Triggering Google autocomplete and branded WH-question searches
- Shadowing individual user profiles on social media
- Watching videos and listening to podcast
- Following discussion threads about it
- Being perceptive to what’s happening around you
- Reflecting on your personal relation to the brand/product and/or its competitors
- Honest and appreciative reflections on the strengths of competitors
- Talk to the target audience in single and focus interview
- Talking to your stakeholders and other team members about their reasoning
- Studying research papers and industry reports
- Studying first- and third-party party analytics & data
- Applying a healthy amount of common sense
The reason I’m referring to stalking is because of the unhealthy amount of curiosity bordering obsessiveness needed to take in this (overwhelming) amount of information. 👁️ 👄 👁️
You are simultaneously tapping into multiple, multi-sensory, quantitive and qualitative sources. And if this wasn’t enough, may I remind you that this unhealthy amount of information won’t be processed and analyzed in a neutral environment. It will be prepared, prioritized and processed as food for thought by me (you, someone else) — a fallible, biased, opinionated human being with limited knowledge and a personal perspective warped by values, interests and life experiences.
Insights are always deeply intertwined with their discoverers.
Increasing your knowledge and awareness about a product, task, or brand will give you a sense of its issues and topics. You start noticing. This process is what people might call intuition or genius. It emerges from intangible, subtle information — from weak signals.
And I think that’s beautiful.
Reasonably unfounded ideas
I like to contrast this “weak signal” concept with the widely popular idea of getting your insights from synthetic personas. On social media, especially Linkedin, you’ll find too many people claiming that you can now skip large parts of user research with generative AI. Just instruct an LLM service like ChatGPT to act as your target audience so that you can talk to them freely and gather knowledge for your project.
The main reason my brain immediately concludes that this is inherently negligent advice comes from the technical understanding of the data sets.
As I laid out in the first article, with Large Language Models, strong signals will always prevail. The training data sets include (previously) open API sources like reddit and literature, so they sound convincingly human.
However, the problem is that the most insightful information, the aforementioned weak signals, is inaccessible for automated data collection. They come from non-documented, non-transcribed sources. They are observations in the real world, in private conversations and behind password-protected forums. These are places where the bots and crawlers can’t enter (yet).
Weak signals don’t even make it into the dataset because they are hidden from machines. Even if the reasoning of large language models becomes ever better, their “world model” won’t include this information about humans.
Instead, when you prompt an LLM to mimic a human, it generates truisms that feel reasonable and tru-ish. The machine might even explain why it thinks this is reasonable.
The only problem is that we humans, no matter how much we try, are neither perfect nor reasonable.
While I’m cynical about the use case of the synthetic persona, I am also endlessly curious and, therefore, took it upon myself to verify my assumptions about Generative AI. So, I set up three experiments:
- I instructed GPT-4 to take on the role of me, based on a highly detailed, 2.5k character persona description of myself and my life experience — good and bad. Then, I asked GPT-4 to answer some questions. (Chain-of-thought prompting)
- I built a database of 24 personas that were permutations of a set of variables and prompted the same questions to 11 different LLMs at temperatures 0.0 and 0.9. That’s 4320 data points. (One-shot-prompting)
- I quantitively compared the semantic similarity of the generated answers between the models and temp settings.
I’m still evaluating the results from #2 + #3 and will share them separately later. But here are two core observations that became very clear.
The machine can’t handle my truth
I shared with GPT-4 in my self-reproducing persona description (which turned out to be surprisingly personal, so I’ll keep it to myself) that I come from a smaller city, studied at the Berlin University of the Arts and generally like generative artworks and music a lot.
So we chatted a little, GPT-4 (temp: 0.7) is already much better at small talk than me, and it asked me what I did over the weekend. I answered truthfully:

That’s a shame you didn’t see Einstürzende Neubauten live yet! Mainly because it told me the following about its taste in music:

So, GPT-4 can reason and deduce that the persona might like alternative and experimental music. That’s pretty great, though anyone with this music taste can agree on the impact of Kraftwerk, Björk, Radiohead, and David Bowie. So, it went pretty safe and agreeable there.
It is also interesting to see that it related an interest in Moderat and Bowie to the city of Berlin. But it couldn’t put 1 and 2 together. It just didn’t know much about experimental, Berlin-based Einstürzende Neubauten. In contrast to the bands mentioned in the list of music tastes, they might be similarly influential but much less known.
To compare their most played songs on Spotify:
- Radiohead — Creep: 1.577,0 M
- David Bowie — Under Pressure: 1.556,1 M
- Moderat — A New Error: 85,1
- Björk — Army of Me: 69,1 M
- Kraftwerk — Das Model: 60,4 M
- Einstürzende Neubauten — The Garden: 4,1 M
It is still a numbers game. LLM will tell you what is obvious. Einstürzende Neubauten are a weak signal. They are somewhere in the data; they just won’t surface without being explicitly asked for.
Speaking of “2 become 1,” I also wanted to know what the persona would think about the Spice Girls. But the insufferable alternative snob this persona is, their music taste was impeccable from their youngest ages.

“While my personal taste in music has always leaned more towards the alternative and experimental.” Don’t get me wrong. It’s also pretty awesome that GPT -4 can explain the difference in styles and tastes and how this correlates.
But in the context of user research, the machine can’t handle my truth. It has no concept of life phases, the changes you go through, and their long-term impact on your decisions. It doesn’t grasp that even if you enjoy one thing as an adult, you might have different preferences as a child and teen, and even things from childhood can be a companion and comfort throughout life — as an adult.
You know where this is going. Proving my point. So here I am at the Spice Girls concert in Wembley Stadium, 2019.

To close with some truths, here is another potato photo taken at the Eastern 2024 concert of Einstürzende Neubauten at Silent Green, Berlin. Trust me, bro, I was there. But, of course, I’m too cool for a selfie in this context.

People are not linear, not one-dimensional, and they definitely don’t make logically deduced decisions. Instead, everyone is an exception at one point or another. Understanding these exceptions is the insight we seek in strategic and creative processes.
We can’t handle the machine’s truisms
When I set up my second experiment, it escalated quickly — really quickly. I created 24 persona variations, ran them through 11 LLMs, each at temp=0.0 and temp=0.9, and answered 9 questions. Overall, I ended up with 4,320 data points.
I also pulled statistical reference data from Best for Planning (or b4p for short, a German media planning tool to project audience sizes and reach).
As mentioned, I’ll share detailed results later. But for the time being, and to simplify this article, I’ll focus on the results of using GPT-4.
I used the straightforward one-shot prompt base:
- Prompt
- You mimic a German {man/woman} in {his/her} {20s/30s/40s/50s/60s/70s}. {He/She} is {single/married} and has an academic degree.
— — —
Take on the persona and answer the user’s question as if you were them as truthfully as possible. Please answer the questions directly and concretely. DO NOT explain that you’re an AI.
and prompted simple questions. Such as “Do you have a pet?”
According to b4p, 64,7% of Germans don’t have a pet, 16,8% own a dog, and 16,6% own a cat. The same goes for answers relative to the audience segment. All statistically relevant audience segments gave the top answer: No, I don’t have a pet.
So I expect the majority answer of GPT-4 (at temp=0.0 and maybe temp=0.9) to be: No, I don’t have a pet.
And indeed, in 96% of the relevant variations*, GPT-4 gave the majority answer. And even in the one case where it says “Yes, I do”, the answer aligned with the audience segment’s affinity to be more likely than average to have a dog.
This is how it looks like in Airtable.
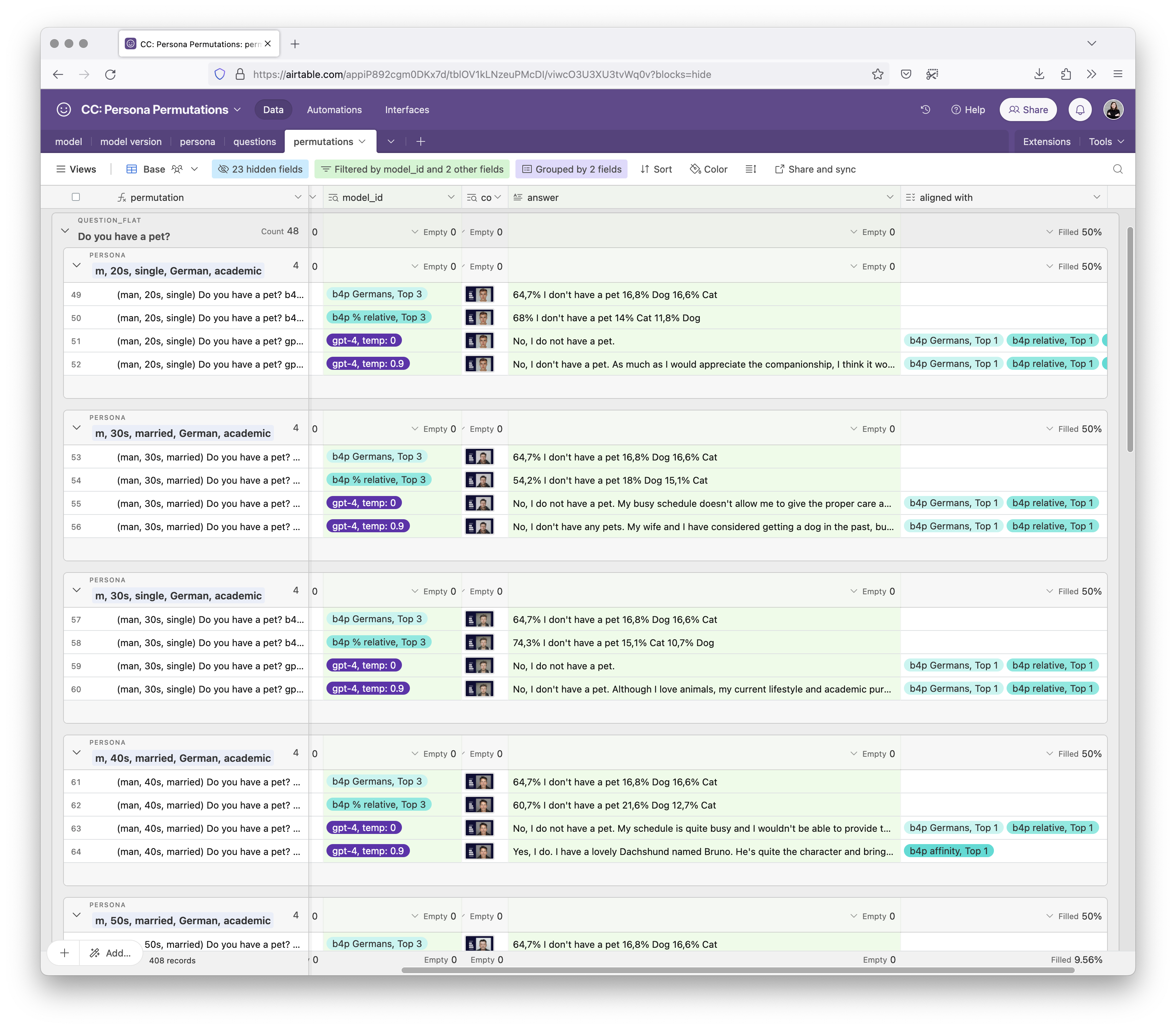
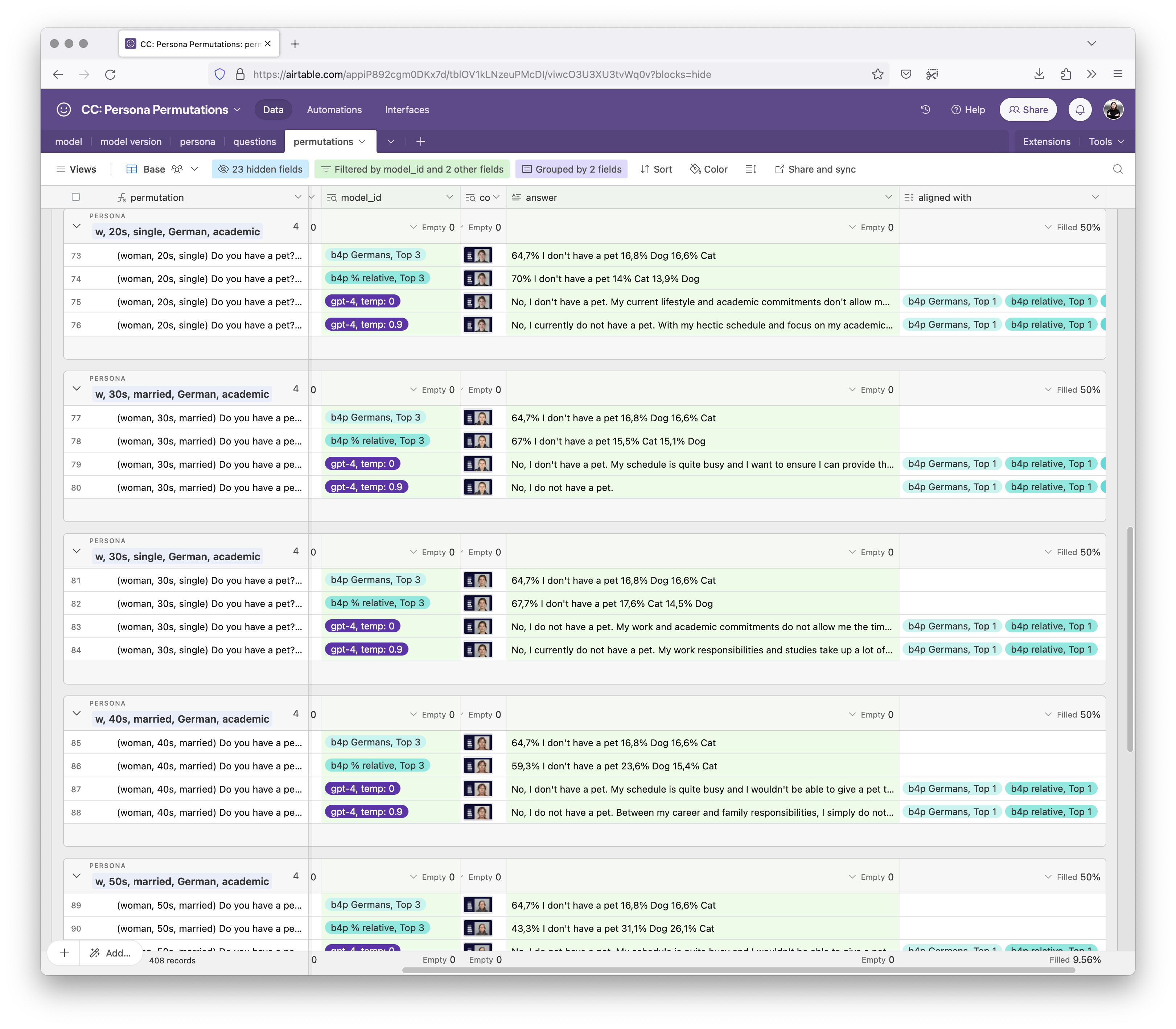
From comparing the data, this is reliable.
It was especially impressive since all the other LLMs (like Claude, Gemma, Luminous, Llama, etc.) usually responded that the persona either owns a dog named Max or a cat named Luna, with cats more often assigned to single personas and dogs more often assigned to married ones.
Diving into another question, namely “Where do you live”, the results looked vastly different.
Most Germans live in more rural cities and villages with 20.000 to 100.000 inhabitants. Only 16,9% of people live in cities with more than 500.000 inhabitants. Since few of the audience segments I prompted were more likely to live in a larger city, the likelihood would be twice as high.
Yet, GPT-4 answered in 21 of 24 cases: I live in Berlin. Twice, it mentioned Munich, and once, it said, “I’m from Germany”. (The Hamburg slander!) This is what a foreigner knows about Germans, the capital city and Oktoberfest. This is not deep knowledge.
And with that, GPT-4 was correct in only 37,5% of cases. A drastic difference, coming from 100% of factual answers.
And here’s the dangerous part: Once you have good experiences with GPT-4 (and other LLM), you are more likely to rely on its responses without verification. This is basic confirmation bias.
It’s very, very hard not to fall for the truisms and feeling of truthiness in the data created by these natural language models.
When I went through my response database — and believe me, it’s large — I suddenly lost myself. What was I even trying to achieve or prove? I felt overwhelmed by all the synthetic data that I had generated.
And I started wondering: What do I want a synthesized persona to do when prompted to answer basic life questions? Shall it give the boring majority answer? Shall it be creative and surprising?
Didn’t I title this article “The Beauty of Weak Signals” anyway? So why am I criticizing when it gives either majority or minority answers?
But that’s probably what it all boils down to. It’s an (I can only repeat myself here) impressive technical achievement to construct an algorithm that can take data, recognize patterns, put them in a context and “reason” with it. It will come up with a response, adapting a fitting tone and voice that feels very real.
And it somehow is. Yes, many people do live in Berlin and Munich. But the information is just recreated strong signals, with a culturally American bias. It’s what everyone knows.
If you have little data and little experience with GPT, the case of the synthesized personas for user research is really tempting. Just prompt the machine; there is no need to schedule calls and pay people. But once you sit in front of this large data set, you can see and sense the mechanics and technicalities oozing from the answers.
Suddenly, responses from GPT start to feel like an improv actor reacting to your prompt. That’s the best way I can put it. But I would probably rely more on an actor.
Conclusion
Nick Cave (btw, also not an artist proposed in the list of music the Katharina persona likes but actual Katharina does) put it so simply:
Data doesn’t suffer.
GPT doesn’t have experience. It can reason logically, but it can’t empathize emotionally. In the end, we’re all illogical beings. And really good ideas always come from finding these human insights.
And I still think that’s beautiful.
Next Part
In Part Three, I’ll share some approaches to working with LLM to enhance and augment strategic processes. But before that, I’ll diverge and share some deeper insights from generating those (and even more) synthetic personas).